About FSM
The Flomesh Service Mesh (FSM) inherits a very small portion of archived OSM code.
- FSM utilizes Flomesh Pipy proxy. This enables FSM to achieve lightweight control and data planes, optimizing CPU and memory resources effectively.
- Implemented traffic interception using eBPF-based technology instead of iptables-based traffic interception. To keep conformance with existing users,
iptablesis the default, while new users during installation can selectebpfoption. - FSM offers comprehensive north-south traffic management capabilities, including Ingress and Gateway APIs.
- Additionally, it facilitates seamless interconnectivity among multiple clusters and incorporates service discovery functionality.
Flomesh Pipy is a programmable network proxy that provides a high-performance, low-latency, and secure way to route traffic between services.
FSM is dedicated to providing a holistic, high-performance, and user-friendly suite of traffic management and service governance capabilities for microservices operating on the Kubernetes platform. By harnessing the combined strengths of FSM and Pipy, we present a dynamic and versatile service mesh solution that empowers Kubernetes-based environments.
Why FSM?
In practice, we have encountered users from a variety of industries with similar requirements for service mesh. These industry users and scenarios include:
- Energy and power companies. They want to build simple server rooms at each substation or gas station to deploy computing and storage capacity for the processing of data generated by devices within the coverage area of that location. They want to push traditional data center applications to these simple rooms and take full advantage of data center application management and operation capabilities
- Telematics service providers. They want to build their simple computing environments in non-data center environments for data collection and service delivery to cars and vehicle owners. These environments may be near highway locations, parking lots, or high-traffic areas
- Retailers. They want to build a minimal computing environment in each store, and in addition to supporting traditional capabilities such as inventory, sales, and payment collection, they also hope to introduce new capabilities of data collection, processing, and transmission
- Medical institutions. They want to provide network capabilities at every hospital, or a simple point of care, so that in addition to providing digital service capability for patients, they can also complete data collection and data linkage with higher management departments at the same time
- Teaching institutions, hospitals, and campuses alike. These campuses are characterized by a relatively regular and dense flow of people. They want to deploy computing resources near more crowd gathering points for delivering digital services, as well as collecting and processing data in real-time
These are typical edge computing scenarios, and they have similar needs:
- Users want to bring the traditional data center computing model, especially microservices, and the related application delivery, management operation, and maintenance capabilities to the edge side
- In terms of the working environment, users have to deal with factors such as power supply, limited computing power, and unstable network. Therefore, computing platforms are required to be more robust and can be deployed quickly or recover a computing environment completely in extreme situations
- The number of locations (we call POP=
Point of Presence) that usually need to be deployed is large and constantly evolving and expanding. The cost of a POP point, the price of maintenance, and the price of expansion are all important cost considerations. - Common, or low-end, PC servers are more often used in these scenarios to replace cloud-standard servers; low-power technology-based computing power such as ARM is further replacing low-end PC servers. On these hardware platforms, which are not comparable to cloud-standard servers, users still want to have enough computing power to handle the growth in functionality and data volume. The conflicting demands of computing moving closer to where the data is generated, the growth in data volume and functional requirements at the edge, and the limited computing resources at the edge require edge-side computing platforms to have better computing power efficiency ratios, i.e., running more applications and supporting larger data volumes with as little power and as few servers as possible
- The fragility and a large number of POP points require better application support for multi-cluster, cross-POP failover. For example, if a POP point fails, the neighboring POP points can quickly share or even temporarily take over the computing tasks.
Compared with the cloud data center computing scenario, the three core and main differences and difficulties of edge computing are:
- Edge computing requires support for heterogeneous hardware architectures. We see non-x86 computing power being widely used at the edge, often with the advantage of low power consumption and low cost
- Edge computing POP points are fragile. This fragility is reflected in the fact that they may not have an extremely reliable power supply, or the power supply is not as powerful as a data center; they may operate in a worse environment than the constant temperature and ventilation of a data center; their networks may be narrowband and unstable
- Edge computing is naturally distributed computing. In almost all edge computing scenarios, there are multiple POP points, and the number of POP points is continuously increasing. the POP points can disaster-proof each other and migrate to adjacent POP points in case of failure, which is a fundamental capability of edge computing
The evolution of Kubernetes to the edge side solves the difficulties of edge computing to a certain extent, especially against fragility; while the development of service mesh to the edge side focuses on network issues in edge computing, against network fragility, as well as providing basic network support for distributed, such as fault migration. In practice, container platforms, as today’s de facto quasi-standard means of application delivery, are rapidly evolving to the edge side, with a large number of releases targeting edge features, such as k3s; but service mesh, as an important network extension for container platforms, are not quickly keeping up with this trend. It is currently difficult for users to find service mesh for edge computing scenarios, so we started the [FSM][1] an open source project with several important considerations and goals, namely
- Support and compatibility with the SMI specification, so that it can meet users’ needs for standardization of service mesh management
- Full support for the ARM ecosystem, which is the “first-class citizen” or even the preferred computing platform for edge computing, and the Service Mesh should be fully adapted to meet this trend. [FSM][1] follows the ARM First strategy, which means that all features are developed, tested, and delivered on the ARM platform first
- High performance and low resources. The service mesh as infrastructure should use fewer resources (CPU/MEM) while delivering higher performance (TPS/Latency) at the edge.
Features
- Light-weight, high-performant, cloud-native, extensible
- Out-of-the-box supports x86, ARM architectures
- Easily and transparently configure traffic shifting for deployments
- Secure service-to-service communication by enabling mutual TLS
- Define and execute fine-grained access control policies for services
- Observability and insights into application metrics for debugging and monitoring services
- Integrate with external certificate management services/solutions with a pluggable interface
- Onboard applications onto the mesh by enabling automatic sidecar injection of Pipy proxy
- Supports Multi-cluster Kubernetes the Kubernetes way by implementing MCS-API
- Supports Ingress/Egress and Kubernetes Gateway API
- Supports protocols like MQTT
Architecture
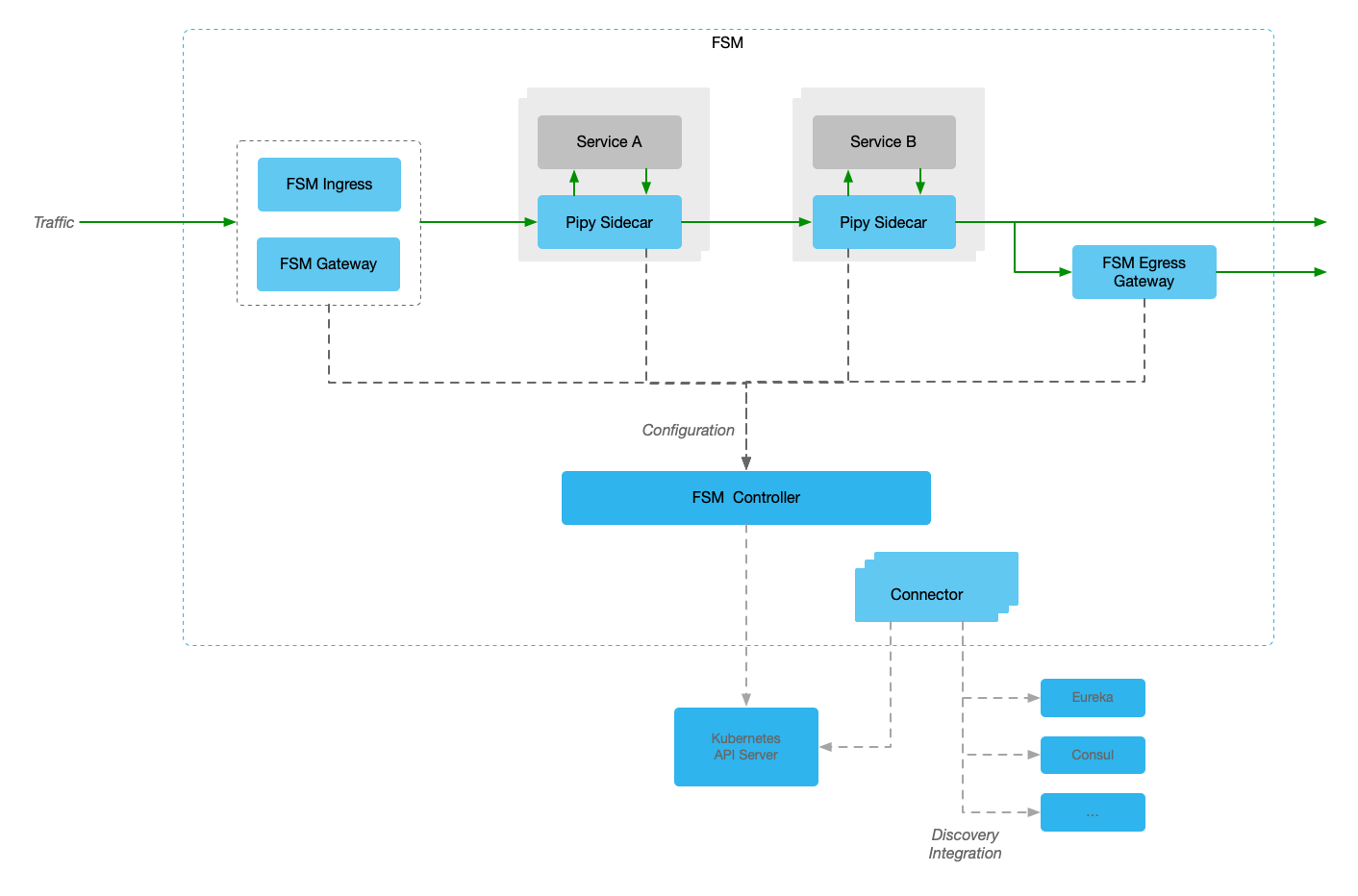
To break the tight coupling on Pipy and open doors for 3rd parties to develop or make use of their data plane or sidecar proxies, we have refactored the FSM v1.1.x codebase to make it generic and provide extension points. We strongly believe in and support open source and our proposal for this refactoring have been submitted to upstream for their review, discussion, and/or utilization.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.