Multi-cluster services
Multi-cluster communication with Flomesh Service Mesh
Kubernetes has been quite successful in popularizing the idea of container clusters. Deployments have reached a point where many users are running multiple clusters and struggling to keep them running smoothly. Organizations need to run multiple Kubernetes clusters might fall into one of the below reasons (not an exhaustive list):
- Location
- Latency (run the application as close to customers as possible)
- Jurisdiction (e.g. required to keep user data in-country)
- Data gravity (e.g. data exists in one provider)
- Isolation
- Environment (e.g. development, testing, staging, prod, etc)
- Performance isolation (teams don’t want to feel each other)
- Security isolation (sensitive data or untrusted code)
- Organizational isolation (teams have different management domains)
- Cost isolation (teams want to get different bills)
- Reliability
- Blast radius (an infra or app problem in one cluster doesn’t kill the whole system)
- Infrastructure diversity (an underlying zone, region, or provider outages does not bring down the whole system)
- Scale (the app is too big to fit in a single cluster)
- Upgrade scope (upgrade infra for some parts of your app but not all of it; avoid the need for in-place cluster upgrades)
There is currently no standard way to connect or even think about Kubernetes services beyond the single cluster boundary, and Kubernetes Multicluster SIG has put together a proposal KEP-1645 to extend Kubernetes Service concepts across multiple clusters.
Flomesh team has been spending time tackling the challenge of multicluster communication, integrating north-south traffic management capabilities into FSM SMI compatible service mesh, and contributing back to the Open Source community.
In this part of the series, we will be looking into motivation, goals, architecture of FSM multi-cluster support, its components.
Motivation
During our consultancy and support to the community, commercial clients, and enterprises we have seen multiple requests and desires (a few of which are cited above) on why they want to split their deployments across multiple clusters while maintaining mutual dependencies between workloads operating in those clusters. Currently, the cluster is a hard boundary, and service is opaque to a distant K8s consumer who may otherwise use metadata (e.g. endpoint topology) to better direct traffic. Users may want to use services distributed across clusters to support failover or temporarily during migration, however, this needs non-trivial customized solutions today.
Flomesh team aims to help the community by providing solutions to these problems.
Goals
- Define a minimal API to support service discovery and consumption across clusters.
- Consume a service in another cluster.
- Consume a service deployed in multiple clusters as a single service.
- When a service is consumed from another cluster its behavior should be predictable and consistent with how it would be consumed within its cluster.
- Allow gradual rollout of changes in a multi-cluster environment.
- Provide a stand-alone implementation that can be used without any coupling to any product and/or solution.
- Transparent integration with FSM service mesh, for users who want to have multi-cluster support with service mesh functionality.
- Fully open source and welcomes the community to participate and contribute.
Architecture
- Control plane
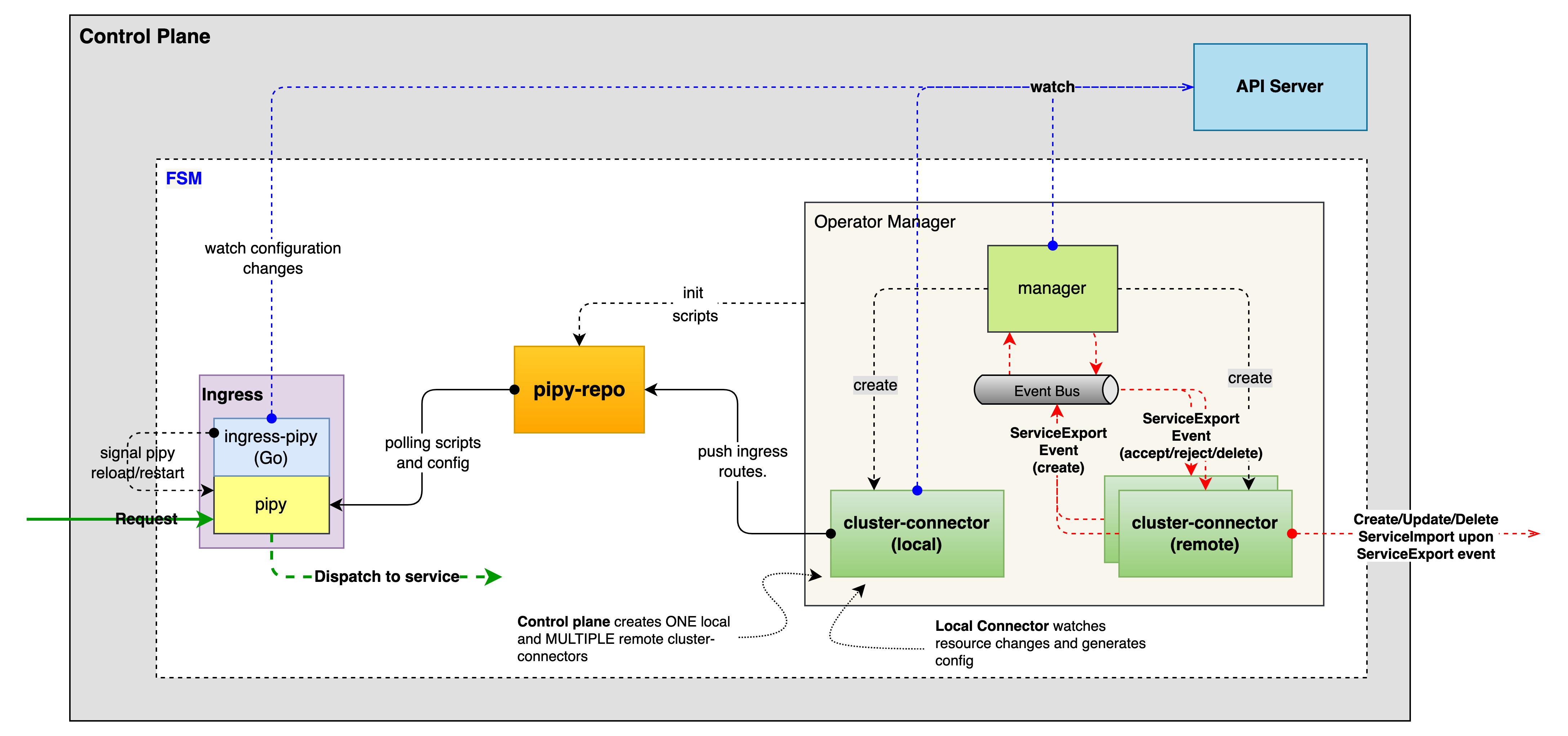
- fsm integration (managed cluster)
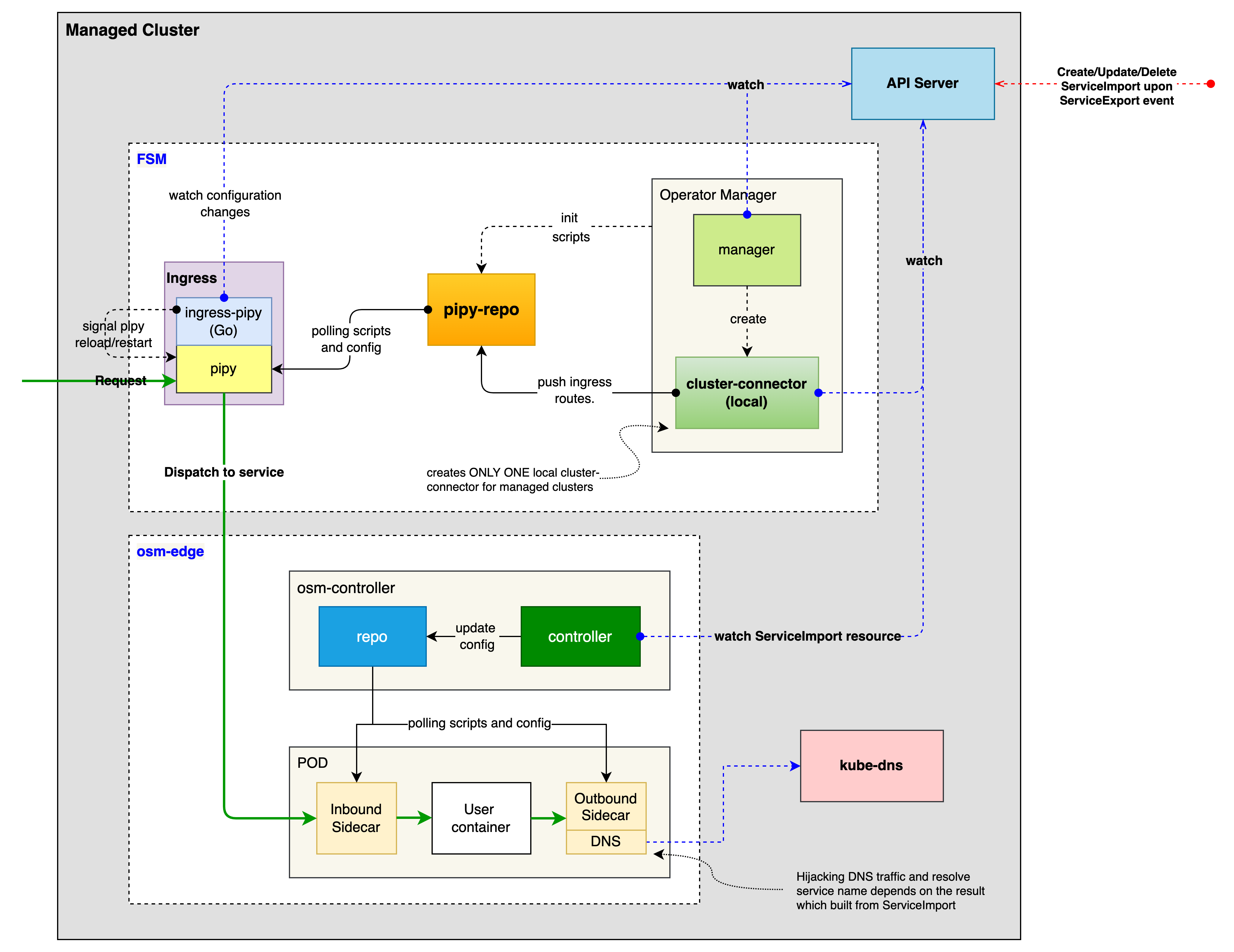
FSM provides a set of Kubernetes custom resources (CRD) for cluster connector, and make use of KEP-1645 ServiceExport and ServiceImport API for exporting and importing services. So let’s take a quick look at them
Cluster CRD
When registering a cluster, we provide the following information.
- The address (e.g.
gatewayHost: cluster-A.host) and port (e.g.gatewayPort: 80) of the cluster kubeconfigto access the cluster, containing the api-server address and information such as the certificate and secret key
apiVersion: flomesh.io/v1alpha1
kind: Cluster
metadata:
name: cluster-A
spec:
gatewayHost: cluster-A.host
gatewayPort: 80
kubeconfig: |+
---
apiVersion: v1
clusters:
- cluster:
certificate-authority-data:
server: https://cluster-A.host:6443
name: cluster-A
contexts:
- context:
cluster: cluster-A
user: admin@cluster-A
name: cluster-A
current-context: cluster-A
kind: Config
preferences: {}
users:
- name: admin@cluster-A
user:
client-certificate-data:
client-key-data:
ServiceExport and ServiceImport CRD
For cross-cluster service registration, FSM provides the ServiceExport and ServiceImport CRDs from KEP-1645: Multi-Cluster Services API for ServiceExports.flomesh.io and ServiceImports.flomesh.io. The former is used to register services with the control plane and declare that the application can provide services across clusters, while the latter is used to reference services from other clusters.
For clusters cluster-A and cluster-B that join the cluster federation, a Service named foo exists under the namespace bar of cluster cluster-A and a ServiceExport foo of the same name is created under the same namespace. A ServiceImport resource with the same name is automatically created under the namespace bar of cluster cluster-B (if it does not exist, it is automatically created).
// in cluster-A
apiVersion: v1
kind: Service
metadata:
name: foo
namespace: bar
spec:
ports:
- port: 80
selector:
app: foo
---
apiVersion: flomesh.io/v1alpha1
kind: ServiceExport
metadata:
name: foo
namespace: bar
---
// in cluster-B
apiVersion: flomesh.io/v1alpha1
kind: ServiceImport
metadata:
name: foo
namespace: bar
The YAML snippet above shows how to register the foo service to the control plane of a multi-cluster. In the following, we will walk through a slightly more complex scenario of cross-cluster service registration and traffic scheduling.
Okay that was a quick introduction to the CRDs, so let’s continue with our demo.
For detailed CRD reference, refer to Multicluster API Reference
Demo
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.